
Data Pipeline: Definition, Process, Tools And Examples
The method of transferring data from one system to a different is termed a “data pipeline”. Data pipelines type the idea for empirical work and square measure so progressively changing into the main target of a data-driven company to create data offered quickly in top quality.
However, there’s a high degree of variance in data pipelines and the way they will be enforced, which we will gift during this article.
What is a data pipeline?
The data pipeline is that the automatic transfer of data from a supply to a destination. Such a pipeline will take several forms: whether or not it’s the consolidation of many files in one report, the transfer of data from a supply system to an information warehouse, or event streaming – there’s an enormous vary of use cases for putting in an information pipeline.
The relevancy of those data pipelines becomes apparent if one thinks of these examples any. Each company owns and processes data – however, the supplemental price sometimes solely arises once knowledge is extracted from its original system and created offered for any process.
Data analytics, data science with machine learning, or just the availability of consolidated data sets for channels like websites or apps square measure all supported data pipelines to offer high-quality data endlessly.
The advantages of an data pipeline square measure obvious: By automating the method, it is often maintained and optimized and is freelance of human skills, understanding, or time.
On the opposite hand, the challenges quickly become apparent if one thing changes within the supply or target systems: knowledge pipelines square measure usually fragile. They have to be compelled to be tailored directly once changes in a square measure are created.
Data pipeline process: ETL vs. ELT
In general, “data pipeline” is the umbrella term for all the world that pushes data from one place to another. However, a distinction is often created between completely different method steps and kinds of processes.
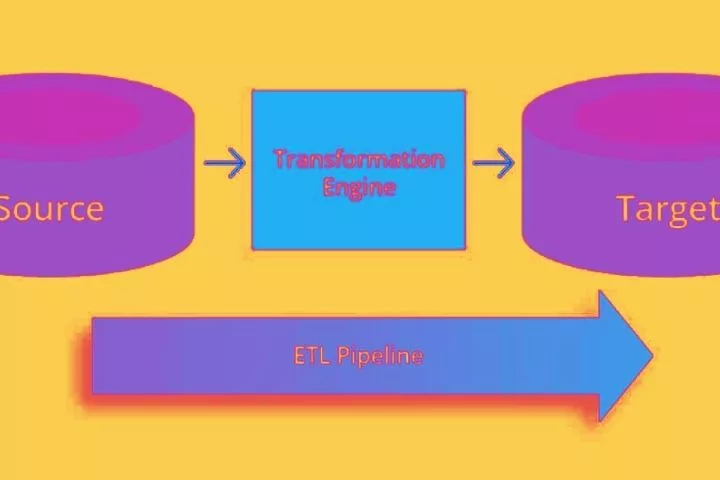
EXTRACT-TRANSFORM-LOAD (ETL): THE CLASSIC approach
The traditionally most conventional process of building an information pipeline is the associate Extract-Transform-Load (ETL) pipeline. Here, data is extracted from a system or a drive, ready in the associate intermediate step so loaded into another system.
These three intermediate steps can even be refined. For instance, the “transform” half also includes the consolidation of data sources with others, identifying and filtering entries with lower knowledge quality, and a lot of.
The “load” half, on the opposite hand, is sometimes not simply the transfer to a different, fastened system; however, it can even mean the availability of the processed data mistreatment associate API or an instrumentality like a stevedore.
EXTRACT-LOAD-TRANSFORM: DATA FOR THE DATA LAKE
One of the frequent modifications to the ETL method in recent years is the ELT method. Since the initial information is processed initially, data may also be lost during this step. The ETL method originally comes from the info repositing space, that structured info is needed.
On the opposite hand, there’s the ELT method. Here the info is initially transferred to a different infrastructure before it’s processed. the concept is to stay the maximum amount of the first type and content as potential. Notably relevant within the data science setting so that the foremost correct machine learning models potential can be trained.
Therefore, the ELT method can even be found primarily within the space of immense data and data lakes. Unstructured data is additionally methods via associate ELT process instead of simply storing the extracted info.
In general, ETL or ELT is additionally referred to as “data ingestion” – that’s, knowledge activity.
Data Pipeline Process: Batch vs. Stream process
Because the process methodology of associate ETL or ELT data pipeline cares, a general distinction is created between 2 varieties.
Instruction execution, during which data is accumulated for an exact amount of your time so processed along, and stream process, during which every event is processed one by one.
BATCH DATA PROCESSING: EFFICIENT BUT SLOW
With a batch data pipeline, knowledge is processed regularly, sometimes once daily or each hour. This has some advantages:
- You’ll operate higher on an oversized variety of expertise.
- It is often scheduled for a time during which there’s minimal load on the core systems.
- A challenging and fast method is usually maintained and expanded.
However, the disadvantages of batch processing are obvious: 24-hour updates aren’t continually adequate. If a perform fails at the start of a posh batch pipeline, issues quickly arise, and errors square measure sometimes solely discovered consecutive days.
However, most of the prevailing data pipelines square measure still in batch format. This is often added because of inheritance systems, i.e., current systems. Whether or not by FTP transfer or info extract: a few years past, there was no thought of mistreatment knowledge extensively within the operational space.
REALTIME STREAM PROCESSING: UP-TO-DATE BUT TIME-CONSUMING
As an alternate to instruction execution, the data stream process, usually referred to as a real-time process, has established itself in recent years. Here, data pipelines don’t wait until an exact purpose for data processing; instead, every event is shipped like a shot and used for alternative functions.
This real-time streaming primarily solves the matter of batch pipelines that the info is usually up-to-date. It’s additionally potential to react like a shot to special events rather than hours or days – notably helpful for police investigation fraud within the banking or money sector, for instance.
On the opposite hand, event pipelines square measure as a lot of sophisticated to integrate and maintain within the IT infrastructure. The expense of each finance and the necessary experience is higher and still discourages some from the mistreatment stream process.
Data pipeline tools
In general, we tend to see four classes of tools for building data pipelines. The main target of every approach varies, and also the combination of various tools could be a matter of fact in several corporations.
SPECIALIZED ETL TOOLS
The specialized ETL / processing tools like Talend, MuleSoft, or Pentaho square measure within the initial class. As a middleware answer, such tools target the task of extracting knowledge from systems, reworking it, and creating it offered mistreatment varied approaches (e.g., via API).
Some of these tools also take consecutive steps and provide different functions within data governance, management, and security. Nonetheless, they’re targeted at building data pipelines to supply knowledge engineers with easy and reparable tools.
PROGRAMMING LANGUAGES
While ETL tools square measure step by step absorbing the sector, the classic approach of building an data pipeline remains implemented via artificial language. In contrast, Python is significantly a lot of most popular within the data science setting, Java or Scala square measure slowly maintaining.
The advantage of a programmed data pipeline is sole that absolute freedom is secured within the implementation. Notwithstanding that interface, transformations, quality, and data use: Everything is feasible because of the liberty from programmed performance.
The disadvantages are obvious. Whereas GUI-based tools are often trained well, and implementation is less complicated mistreatment standardized processes, code must be enforced and maintained terribly} very specialized manner.
The implementation itself additionally takes longer on the average, since ETL tools, for instance, offer standardized interfaces directly, whereas you’ve got to implement them once more within the code.
CLOUD
If you’re employed in an exceeding cloud setting, such thoughts square measure sometimes removed from you. Each more extensive cloud supplier has its ETL suite (e.g., Azure knowledge industrial plant, AWS Glue) with that data pipelines are often seamlessly integrated into the infrastructure. Of course, pipelines can even be enforced manually (e.g., mistreatment associate AWS EC2 instance); however, this is often solely necessary in rare cases.
STANDALONE / data processing TOOLS
The last class is general data processing tools. For instance, KNIME or Rapid Minder have all the functionalities to make ETL or data science pipelines. The matter with these GUI-based tools is that they will neither run in an exceeding cloud setting nor integrate seamlessly with alternative processes.
Nonetheless, some corporations place confidence in GUI-based data pipelines to create data engineers during this space as redundant as potential and to cut back the upkeep effort.
Examples of data pipelines
At the article’s tip, we might prefer to show three samples of data pipelines. For instance, the uses vary.
FILE READER INTO DW
A common purpose is to easily browse in and reformat a get into order to transfer it to an information warehouse. For instance, one masses associate surpass file via Python, applying transformation operations to save them in associate Oracle info mistreatment SQL. From there, it is often visualized, for instance, mistreatment of Google data Studio.
This approach could be a classic use case to run a batch operation nightly.
PRODUCT info API
A Product info API, for instance, incorporates an entirely different focus. For example, info from PIM-associated ERP is often forcing along and consolidated mistreatment of an ETL tool to then deliver it via associate API.
Whether or not as a file or REST API – the availability of compact knowledge sources to entirely different channels usually incorporates a high supplemental price within the company.
IOT EVENT STREAMING
As a 3rd example, a somewhat advanced pipeline that transfers data from a web of Things-based edge device to the cloud. Event streaming is employed to play the info in real-time, replicate it in unstructured associate information and perform on-stream analytics. The info volume and quality consequently need a high level of experience and observance.





